The capabilities of large language models (LLMs) have been a topic of fascination, especially with models like the GPT-4 powering conversational tools like ChatGPT. Recently, researchers from UC San Diego delved into the world of LLMs by conducting a Turing test, a method devised to gauge the level of human-like intelligence exhibited by machines. The results of this test, detailed in a paper available on the arXiv server, revealed some intriguing findings that question the boundaries between machine-generated and human-generated content.
The first study conducted by the researchers, led by Cameron Jones under the supervision of Professor Bergen, hinted at the potential of GPT-4 to pass as a human in about half of the interactions. However, the initial experiment lacked control over certain variables that could impact the results. As a response, a second experiment was carried out to address these limitations and elevate the quality of the findings presented in their recent publication. The intent was clear – to ascertain whether LLMs, particularly GPT-4, could convincingly mimic human responses in a conversational setting.
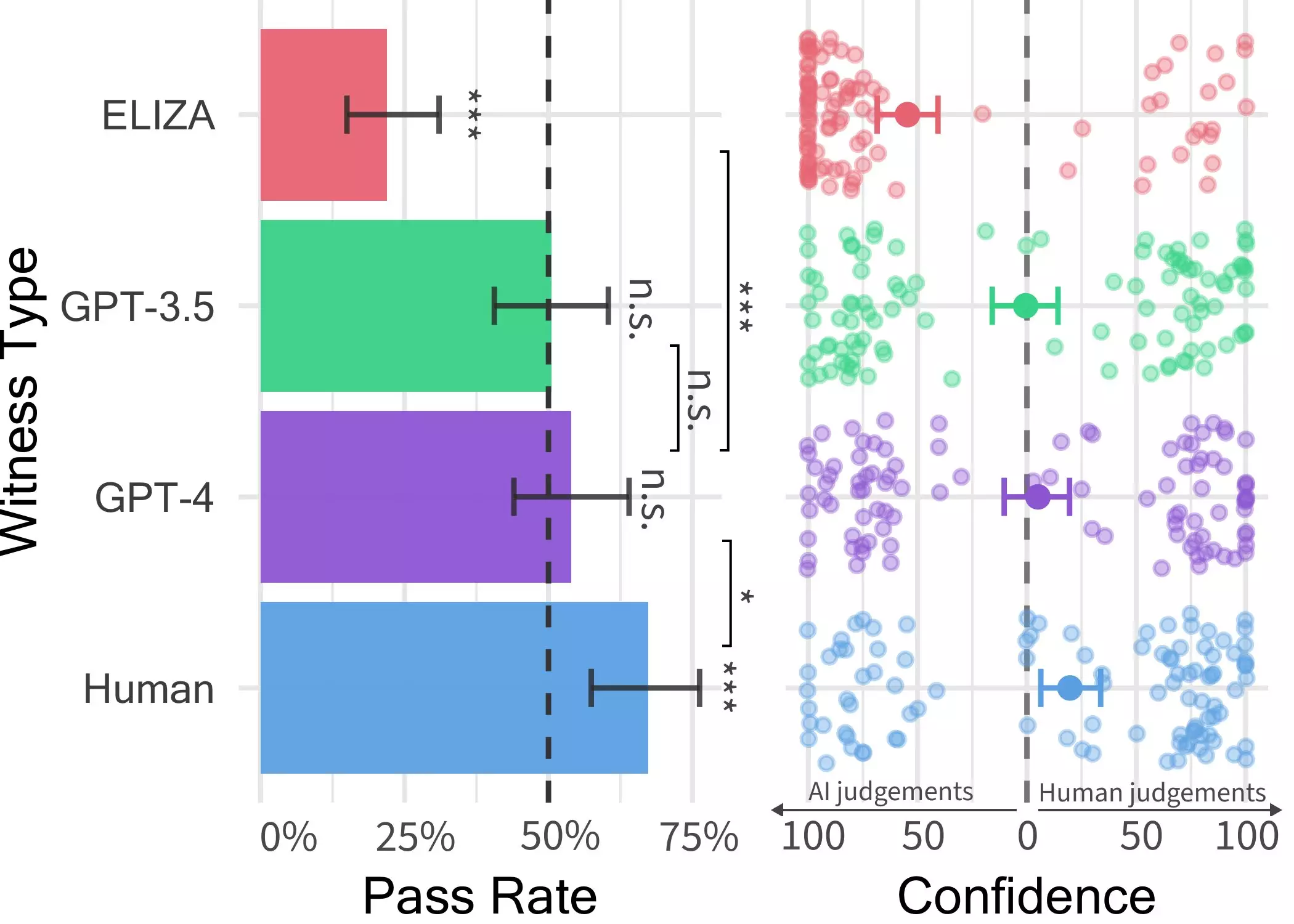
The crux of the experiment lay in a two-player game scenario designed by Jones and his team, where an interrogator engaged with a witness, who could either be human or an AI agent. Over a series of questions and interactions lasting up to five minutes, the interrogator aimed to discern the nature of the witness – human or machine. The variety of topics discussed during these interactions was left open, with the only restriction being the prevention of abusive language through a filtering mechanism.
The game involved three different LLMs as potential witnesses – GPT-4, GPT 3.5, and ELIZA models. While participants could often identify ELIZA and GPT-3.5 as non-human entities, their ability to differentiate GPT-4 from a human was no better than random chance. This finding is particularly significant as it raises questions about the verisimilitude of conversations with LLMs, indicating that distinguishing between human and machine participants might become increasingly challenging in online interactions.
Jones highlighted the broader implications of their findings, suggesting that in real-world scenarios, people may struggle to ascertain whether they are conversing with an AI system or a human. This lack of awareness could have far-reaching consequences, especially in domains like client-facing roles, fraud detection, or disseminating misinformation. The results of the Turing test underscore the growing sophistication of LLMs like GPT-4, blurring the lines between human and machine-generated content.
Looking ahead, the researchers plan to expand their study by introducing a three-person version of the game, where the interrogator engages with both a human and an AI system simultaneously. This setup aims to push the boundaries further, challenging the ability of participants to discern between human responses and those generated by LLMs. By revisiting and enhancing their public Turing test, the team hopes to glean deeper insights into the evolving dynamics of human-machine interactions in the age of advanced language models.
Leave a Reply