In the realm of deep learning, the power of large datasets is both a boon and a bane. While having expansive datasets can drive the performance of algorithms, they often harbor a hidden menace: label noise. This inconsistency in data labeling can critically undermine the model’s ability to generalize learning, leading to subpar classification performance when evaluated on unseen data. As deep learning continues to penetrate various fields—from healthcare to finance—the demand for solutions that tackle these noisy dataset challenges becomes paramount.
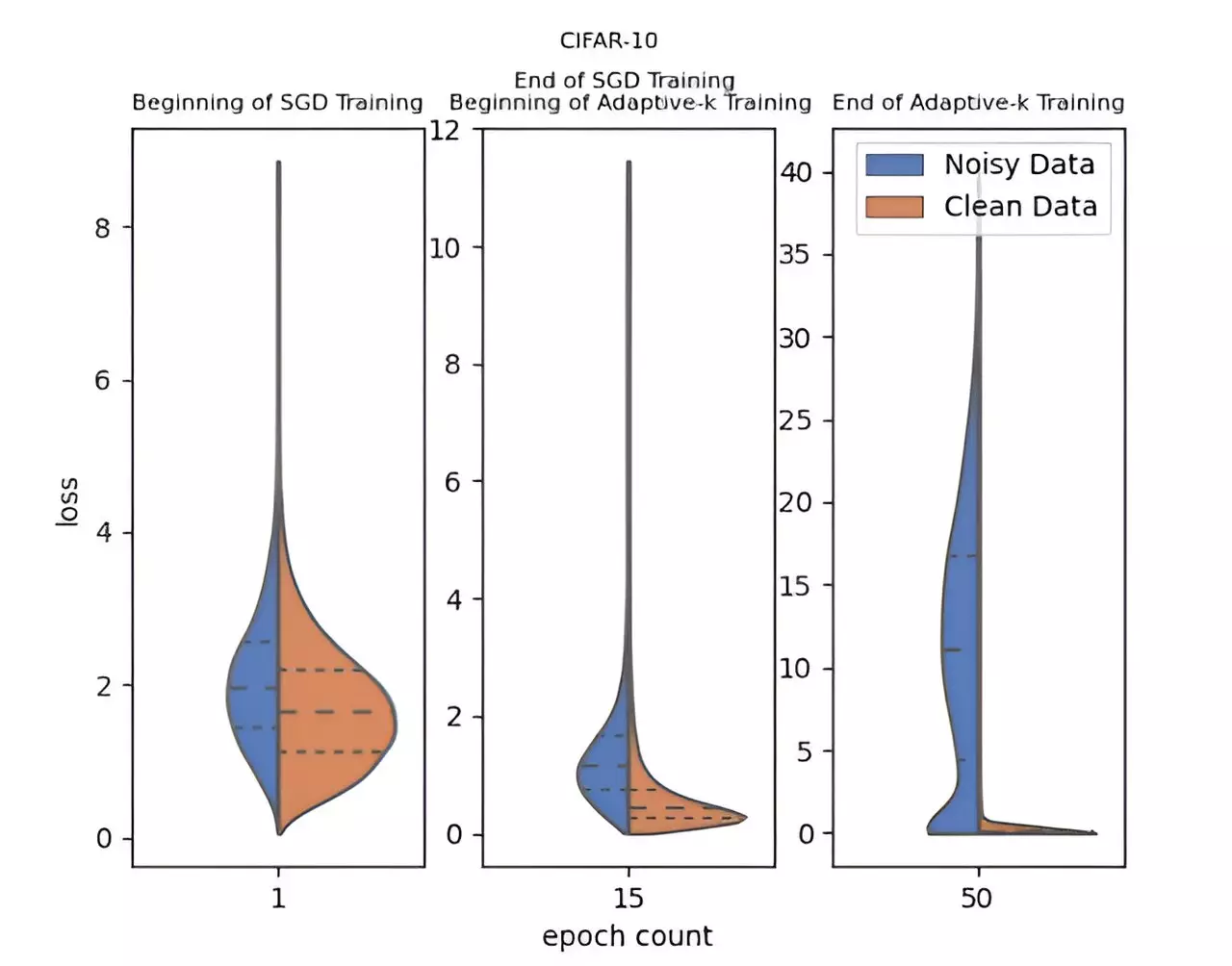
Researchers from Yildiz Technical University, including Enes Dedeoglu, H. Toprak Kesgin, and Prof. Dr. M. Fatih Amasyali, have risen to meet this pressing challenge with an innovative approach called Adaptive-k. Their method transforms the way deep learning models can be trained with noisy data. Unlike conventional algorithms that often require extensive computational resources or prior knowledge of dataset characteristics, Adaptive-k simplifies the optimization process remarkably. It adaptively selects the number of samples used for updates from the mini-batch, ensuring minimal interference from noisy labels while maximizing the model’s learning efficiency.
The robustness of the Adaptive-k method shines through its empirical evaluations against other prominent algorithms, such as Vanilla and MKL. In addition to these baseline models, the team benchmarked Adaptive-k against the Oracle method, which assumes that all noisy labels can be perfectly identified and removed. Their findings decisively indicate that Adaptive-k can achieve performance nearly on par with the Oracle benchmark, demonstrating its effectiveness and potential towards redefining the training landscape for noise-riddled datasets.
The research articulates not only the practical advantages of Adaptive-k but also its theoretical foundations. By grounding the method in rigorous analysis and comparison with established algorithms, the researchers lay claim to significant contributions in the field, providing a framework that future research might build upon.
Perhaps one of the most compelling attributes of the Adaptive-k method is its versatility. Compatible with various optimizers—including SGD, SGDM, and Adam—it promises to integrate seamlessly into existing deep learning workflows without necessitating overhauls or significant computational investment. This adaptability suggests a bright future for the method within diverse applications, from image processing to text analysis, as empirical tests across three image and four text datasets have so far shown consistent superiority against label noise.
Looking ahead, the researchers highlight plans for additional refinements and the exploration of further applications for Adaptive-k. As deep learning evolves, refining methods that bolster robustness against label noise is essential. This research not only contributes a powerful tool to the toolkit of data scientists and machine learning engineers but also opens up avenues for future innovations in model training methodologies.
The impact of Adaptive-k could very well signify a turning point in the management of noisy datasets, aligning practicality with efficiency in the ever-evolving landscape of deep learning.
Leave a Reply