The journey from conception to market for a new drug is often likened to navigating a labyrinthine gauntlet, marked by years of rigorous testing and staggering financial investment. The daunting reality is that over 90% of pharmaceutical candidates fail during clinical trials. Even prior to this critical phase, many potential therapies are discarded due to safety concerns. This high attrition rate not only represents a loss of capital for investors but also delays the availability of potentially life-saving treatments for patients. The traditional methodologies for assessing drug safety are both time-consuming and resource-intensive. However, emerging technologies are beginning to transform this landscape, offering exciting possibilities for streamlining drug development with unprecedented precision.
AI to the Rescue
Researchers at the Broad Institute of MIT and Harvard are leading the charge in harnessing artificial intelligence to fortify the drug discovery process. Specifically, they are working to implement machine learning models that predict the potential biological effects of drugs before they are administered to living organisms. Srijit Seal, a visiting scholar at the Carpenter-Singh Lab, has integrated multiple predictive models aimed at identifying potentially toxic chemical features of drugs. This groundbreaking work can significantly diminish the time and resources allocated to the less promising candidates while redirecting focus to the most viable options.
By utilizing AI-driven analytical tools, researchers can predict various key parameters including general cellular health, pharmacokinetics, and potential impacts on vital organs such as the heart and liver. This novel approach does not intend to eliminate traditional laboratory experiments but rather to complement them by providing a meaningful framework for narrowing the selection of drug candidates that warrant further investigation.
Understanding Toxicity: A Delicate Balance
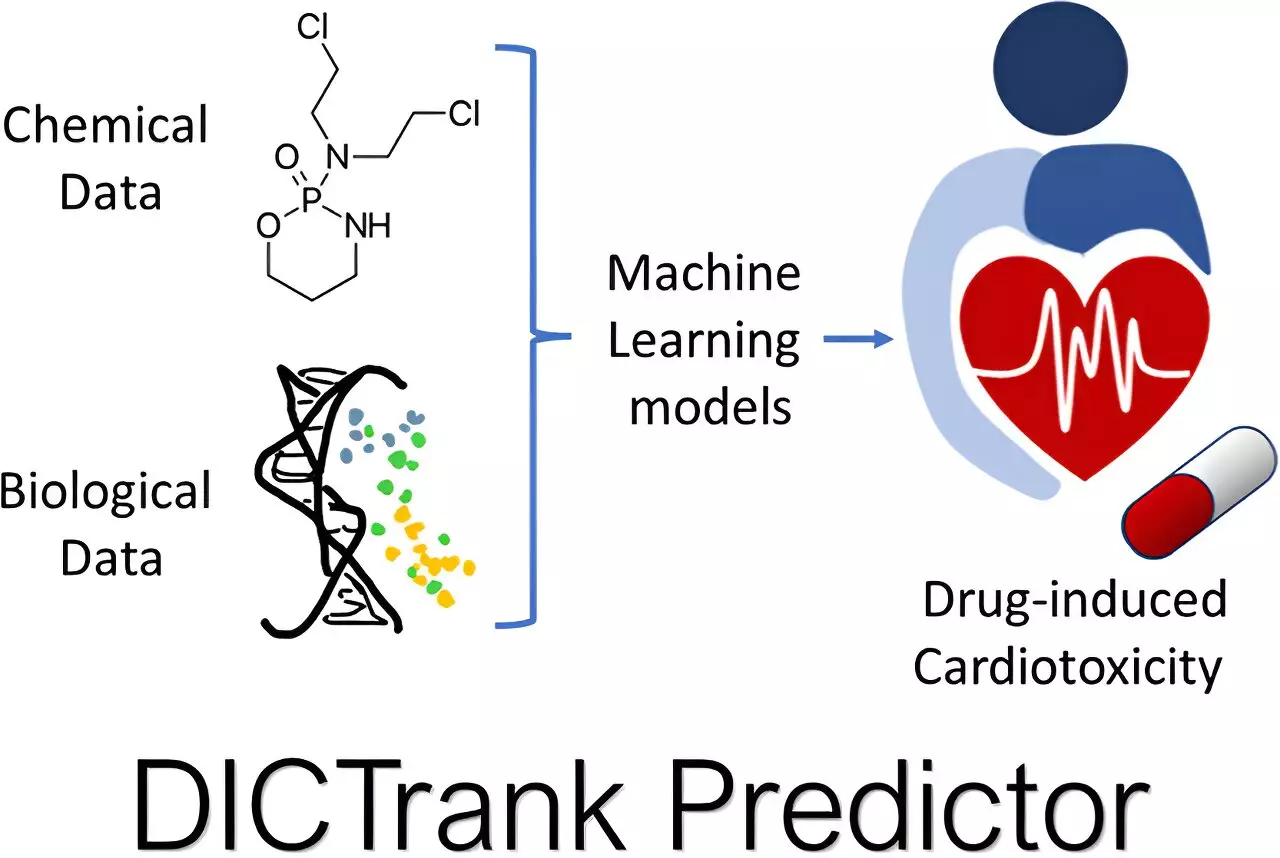
A fundamental aspect of drug development hinges on the understanding of toxicity, a realm where even the most well-intended pharmaceuticals can incur adverse effects post-marketing. Notably, drug-induced cardiotoxicity (DICT) and drug-induced liver injury (DILI) contribute significantly to the withdrawal of drugs from the market after approval. To tackle this challenge, the FDA has compiled categorical datasets revealing various drug compounds’ likelihood of causing harm. Seal and his team sought to leverage these existing databases through machine learning algorithms that can discern structural features tied to toxic outcomes.
Two primary machine learning models emerged from this initiative: one focused on predicting cardiotoxicity and another on identifying potential liver damage. These predictive frameworks employ sophisticated inputs such as chemical structures and physicochemical properties to construct a more accurate representation of a drug’s safety profile, thus acting as an early-warning system for harmful effects before human testing.
Pharmacokinetics: The Elusive Grail
In tandem with toxicity predictions, understanding pharmacokinetics—the way a drug is absorbed, distributed, metabolized, and cleared—is essential for ensuring therapeutic efficacy. Drugs that do not reach the intended target are ineffective, while those that linger too long in the system risk inducing toxicity. The challenge of accurately modeling these pharmacokinetic properties requires substantial expertise and advanced technology. Seal’s efforts are focused on designing predictive pharmacokinetic models, with the ambition of automating what has traditionally been a manual and cumbersome process. This could revolutionize how drug developers assess candidate viability, allowing them to foster innovation while minimizing wasted efforts on ineffective compounds.
Bridging the Gap between Data and Biological Context
As data-driven technologies proliferate, the ability to translate complex datasets into meaningful biological insights becomes increasingly crucial. Recognizing this gap, Seal has developed a deep learning model, BioMorph, which aims to connect imaging data with cell health metrics. This innovative model utilizes outputs from CellProfiler—an open-source tool for analyzing cellular characteristics—and interprets how these changes correlate with the effects of various drug compounds.
BioMorph goes beyond mere prediction; it empowers scientists to glean actionable insights from their data, interpreting cellular responses in a biological context that was previously elusive. The combination of quantitative metrics with visually driven data enables a more comprehensive understanding of how potential therapies interact with cellular systems—ultimately enriching the drug discovery process.
A Paradigm Shift in Drug Discovery
These advancements in AI and machine learning signal a paradigm shift in the field of drug development, pushing the boundaries of what is possible. The ability to better predict toxicity, understand pharmacokinetics, and make sense of complex datasets can fundamentally change how drugs are developed and tested. As these technologies mature, they promise not only to enhance the efficiency of drug discovery but also to usher in a new era of medicine where safer and more effective treatments can be delivered to those who need them most. By intertwining biology and technology, the path to curing diseases may become shorter and clearer than ever before.
Leave a Reply