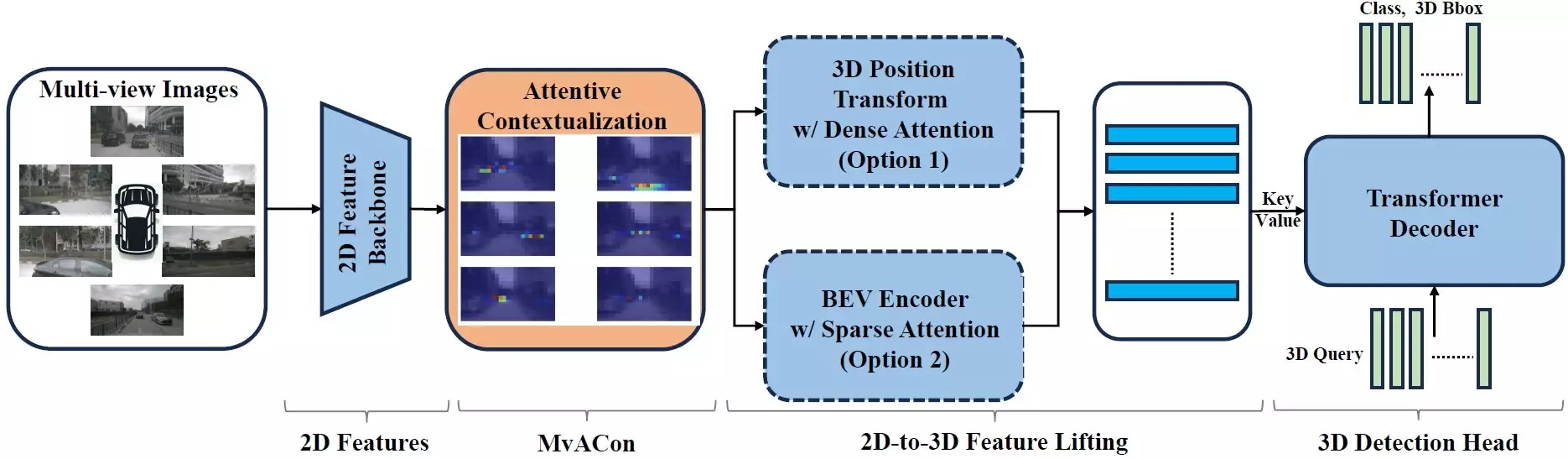
Artificial intelligence (AI) continues to make significant strides in various fields, including the navigation of autonomous vehicles. Researchers have developed a technique known as Multi-View Attentive Contextualization (MvACon) that enhances the ability of AI programs to map three-dimensional spaces using two-dimensional images from multiple cameras. This innovation shows promise in improving the navigation and overall performance of autonomous vehicles.
Most autonomous vehicles rely on powerful AI programs called vision transformers to create representations of the 3D space around them using images from multiple cameras. However, there is still room for improvement in how these AI programs interpret and map the surrounding environment. MvACon serves as a plug-and-play supplement that can be integrated with existing vision transformer AIs to enhance their 3D mapping capabilities without the need for additional data from cameras. By leveraging the Patch-to-Cluster attention (PaCa) approach, MvACon optimizes the identification of objects in images, thereby improving the overall performance of vision transformers in mapping 3D space.
To evaluate the effectiveness of MvACon, researchers conducted tests using three leading vision transformers – BEVFormer, BEVFormer DFA3D variant, and PETR – in conjunction with images from six different cameras. The results showed a significant improvement in the performance of each vision transformer, particularly in terms of object localization, speed, and object orientation. Despite the enhancements brought by MvACon, the additional computational demand imposed on the vision transformers was minimal. These findings demonstrate the potential of MvACon in advancing the capabilities of AI programs in mapping 3D spaces.
Moving forward, researchers plan to further evaluate MvACon by testing it against additional benchmark datasets and real-world video inputs from autonomous vehicles. If MvACon continues to outperform existing vision transformers, there is optimism that it will be widely adopted for various applications. The eventual integration of MvACon into autonomous vehicles could lead to more accurate and efficient navigation systems, thereby improving overall safety and performance.
The development of MvACon represents a significant advancement in the field of artificial intelligence, particularly in mapping 3D spaces using images from multiple cameras. By enhancing the capabilities of existing vision transformers, MvACon opens up new possibilities for improving the navigation and performance of autonomous vehicles. As researchers continue to innovate and refine AI technologies, the potential for further advancements in mapping, object detection, and overall spatial awareness remains promising.
Leave a Reply