In the burgeoning digital landscape, Large Language Models (LLMs) have emerged as transformative tools that significantly influence various aspects of our daily interactions. From drafting emails to facilitating online searches, LLMs like ChatGPT are now commonplace, showcasing the remarkable advancements in artificial intelligence (AI). However, as academia and industry explore the implications of these technologies, a comprehensive analysis in Nature Human Behaviour sheds light on both the promising and perilous consequences tied to the utilization of LLMs, particularly concerning collective intelligence.
Research led by a multidisciplinary team from the Copenhagen Business School and the Max Planck Institute for Human Development highlights the duality of LLMs’ impact—how they can bolster our shared decision-making capabilities while simultaneously posing serious risks if they shift the locus of knowledge reliance away from human expertise.
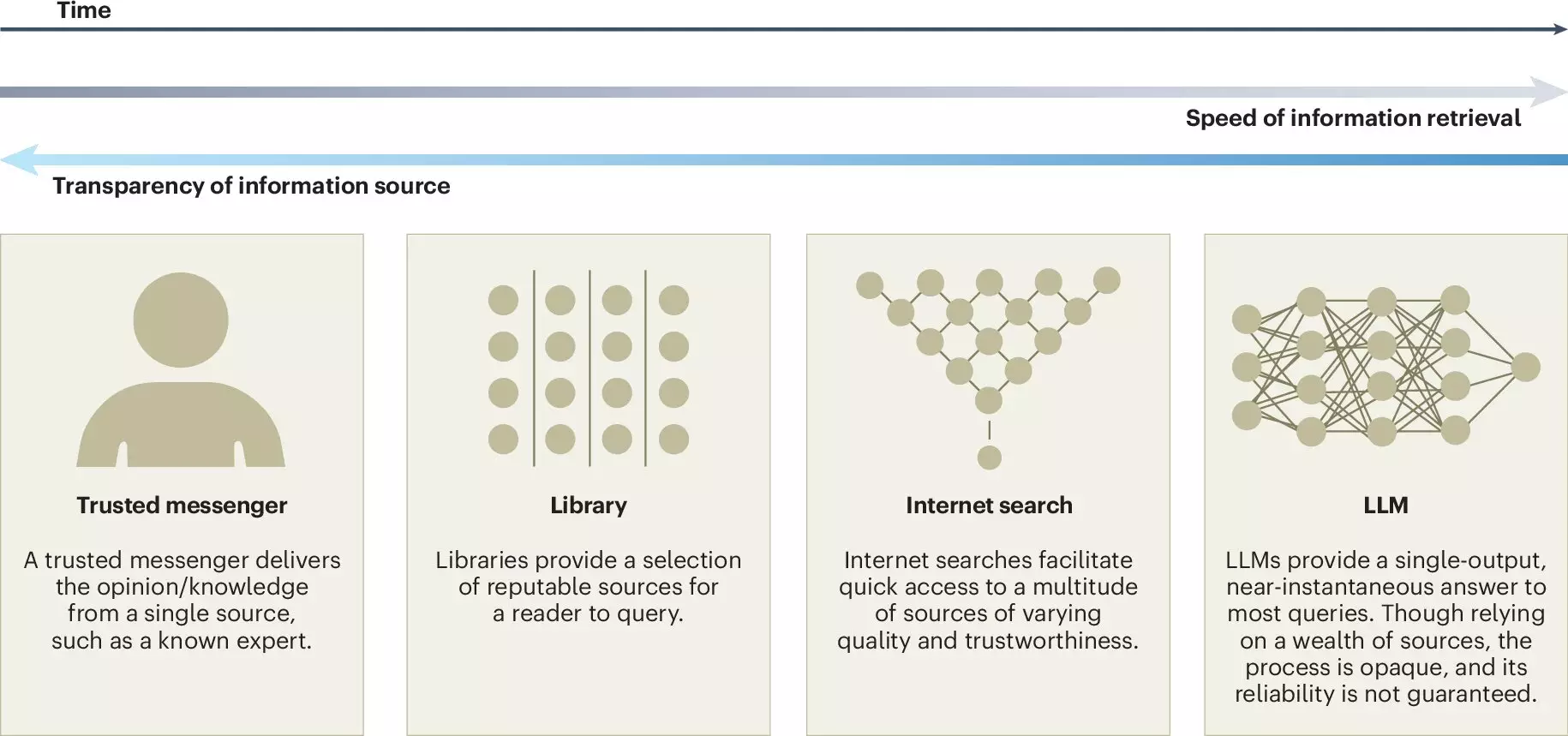
Collective intelligence refers to the collaborative capacity that groups exhibit, often leading to outcomes that outshine the abilities of individuals, regardless of their expertise. We regularly tap into this vast reservoir of knowledge in various forms—from workplace collaborations to large-scale community efforts like Wikipedia. This synergy enables diverse viewpoints that foster innovation and cultivate resilience in problem-solving.
LLMs play an intriguing role in augmenting collective intelligence. By analyzing extensive datasets, these AI systems generate text that can enhance discussions, funnel ideas, and facilitate consensus-building within groups. The article emphasizes that the effective application of LLMs in collective settings could substantially improve how teams communicate and make decisions.
The potential advantages of incorporating LLMs into collective intelligence frameworks are numerous. For one, LLMs democratize access to knowledge. By providing translation services and writing support, they empower participants from various linguistic and educational backgrounds to engage meaningfully in discussions. This accessibility broadens participation and promotes equity, reducing the barriers that often hinder collaboration.
Additionally, LLMs can catalyze idea generation by summarizing differing viewpoints, contextualizing discussions, and even facilitating real-time feedback. By acting as a bridge between disparate perspectives, these models help combat fragmentation within discussions, ensuring a comprehensive exploration of the topic at hand. Ralph Hertwig, a key figure in the research effort, notes, “It’s crucial to strike a balance between harnessing their potential and safeguarding against risks.”
However, the myriad benefits of LLMs come hand-in-hand with potential drawbacks. A significant concern is the chilling effect that reliance on these models might have on the contributions to collective knowledge platforms like Wikipedia and Stack Overflow. As users turn to LLMs for readily available information, the incentive to share personal insights or expertise may diminish. This trend risks eroding the diversity and richness of collective knowledge, as proprietary models can stifle open-source collaboration.
Another pressing issue highlighted is the phenomena of false consensus and pluralistic ignorance. When responding to inquiries, LLMs often echo the majority perspective represented in their training data. This can create an illusion of agreement among users, marginalizing minority viewpoints and fostering a skewed representation of collective thought. Jason Burton, the study’s lead author, articulates this concern, emphasizing the potential for LLM-generated outputs to inadvertently render diverse perspectives invisible.
Given the complex interplay between opportunity and risk, it becomes imperative for developers and researchers to adopt a proactive stance regarding LLM deployment. The article calls for increased transparency in the development processes of LLMs, including clear disclosures about the sources of training data. Additionally, instituting external audits and monitoring can create accountability, allowing stakeholders to gauge the ethical implications of these models more accurately.
The authors put forth the necessity of crafting a framework that not only emphasizes the diverse representation within the training sets but also prioritizes the distribution of credit and accountability when LLMs assist in producing collective outcomes. Exploring open research questions around the homogenization of knowledge and the preservation of unique voices is vital for navigating the landscape of AI in collaborative environments.
The integration of LLMs into our collective intelligence systems represents both an opportunity and a challenge. While they offer tools for enhanced communication and idea generation, we must remain vigilant about the risks they pose. As society continues to grapple with the implications of AI, fostering an environment where collective intelligence thrives alongside responsible AI development will be key to unlocking the full potential of these technologies. By striking this balance, we can harness the strengths of LLMs while safeguarding the rich tapestry of human insight and innovation.
Leave a Reply